Your backups on the USB flash drives are in danger
When I make backup on a USB flash drives I always make two copies of the files and of course make a sha512 checksum.
I tested my archives and find out that one of the files is corrupted. There was no error messages like "file i/o error" or something. Just checksum was not correct. When I inspected the corruption, I found out that there are more than 100 different bytes.
I tried to watch the difference with meld, but it loads the files too slow.
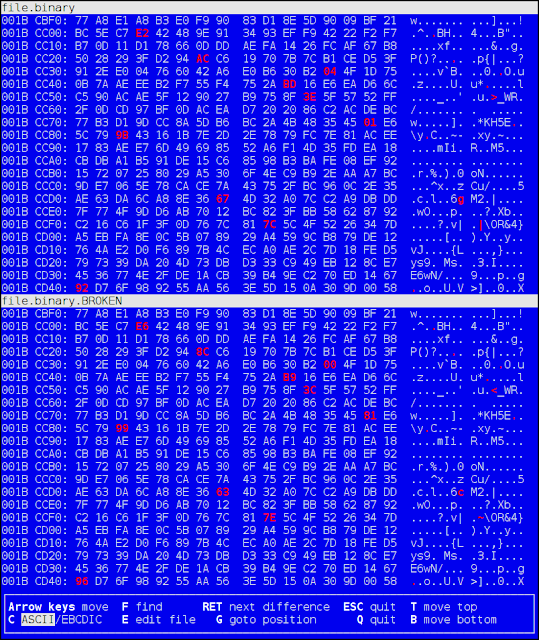
The best hex diff is probably vbindiff. It works in the console and have nice blue colours (like Midnight Commander and old DOS programs):

It turns out that the RAR's "recovery records" are not anachronism.
I have idea of using software RAID 1 array of partitions on one or several USB flash drives (more than one partition per drive) for secure short term backup (because in the long term, electrical charges will leak and information will disappear).
But, as far as I understand it, when using software RAID 1 array, the software do not compare the information between different elements of the array. This is why reading speed is greater when RAID 1 is used. The software rely on error messages from the OS (CRC errors or something). But according to my experience, there is no error messages - I was able to make a copy of the corrupted copy of the file without a single error message!
Therefore, if I make RAID1 array of partitions (on USB flash drives), the array will not work correctly - errors will not be detected by the software.
Can you prove that my theory is wrong? The main proof of my theory is "there was no error message when I copied corrupted copy of a file from an USB flash drive".
Do not use (only) flash memory (SSD drives, hardware wallets, USB flash drives) for your precous private keys!
I tested my archives and find out that one of the files is corrupted. There was no error messages like "file i/o error" or something. Just checksum was not correct. When I inspected the corruption, I found out that there are more than 100 different bytes.
$ hexdump file1.corrupted.binary > file1.txt $ hexdump file1.ok.binary > file2.txt $ diff file1.txt file2.txt > read.diff $ cat read.diff | grep \> | wc -l 131 $ gedit read.diff
I tried to watch the difference with meld, but it loads the files too slow.
The best hex diff is probably vbindiff. It works in the console and have nice blue colours (like Midnight Commander and old DOS programs):

It turns out that the RAR's "recovery records" are not anachronism.
I have idea of using software RAID 1 array of partitions on one or several USB flash drives (more than one partition per drive) for secure short term backup (because in the long term, electrical charges will leak and information will disappear).
But, as far as I understand it, when using software RAID 1 array, the software do not compare the information between different elements of the array. This is why reading speed is greater when RAID 1 is used. The software rely on error messages from the OS (CRC errors or something). But according to my experience, there is no error messages - I was able to make a copy of the corrupted copy of the file without a single error message!
Therefore, if I make RAID1 array of partitions (on USB flash drives), the array will not work correctly - errors will not be detected by the software.
Can you prove that my theory is wrong? The main proof of my theory is "there was no error message when I copied corrupted copy of a file from an USB flash drive".
Do not use (only) flash memory (SSD drives, hardware wallets, USB flash drives) for your precous private keys!






Comments
Post a Comment